Back at Mapbox I worked about a bunch of interesting geospatial tools in addition to the nuts and bolts of building a SaaS product. I also did a lot of other stuff, much of which I’ve continued to do in my roles since then. But that particular combination of fun geospatial problem solving and getting a service off the ground - I’ve missed that and wanted to revisit it.
I set off to do a quick project to scratch that itch. My main goal was to take a try at optimizing queries to Morton ordered data. I had used various space-filling curves, like Morton (also called Z-order), to index geospatial data but I didn’t have the chance to try optimizing how the index is queried. I wanted to give it a shot, so I started a project to do so.
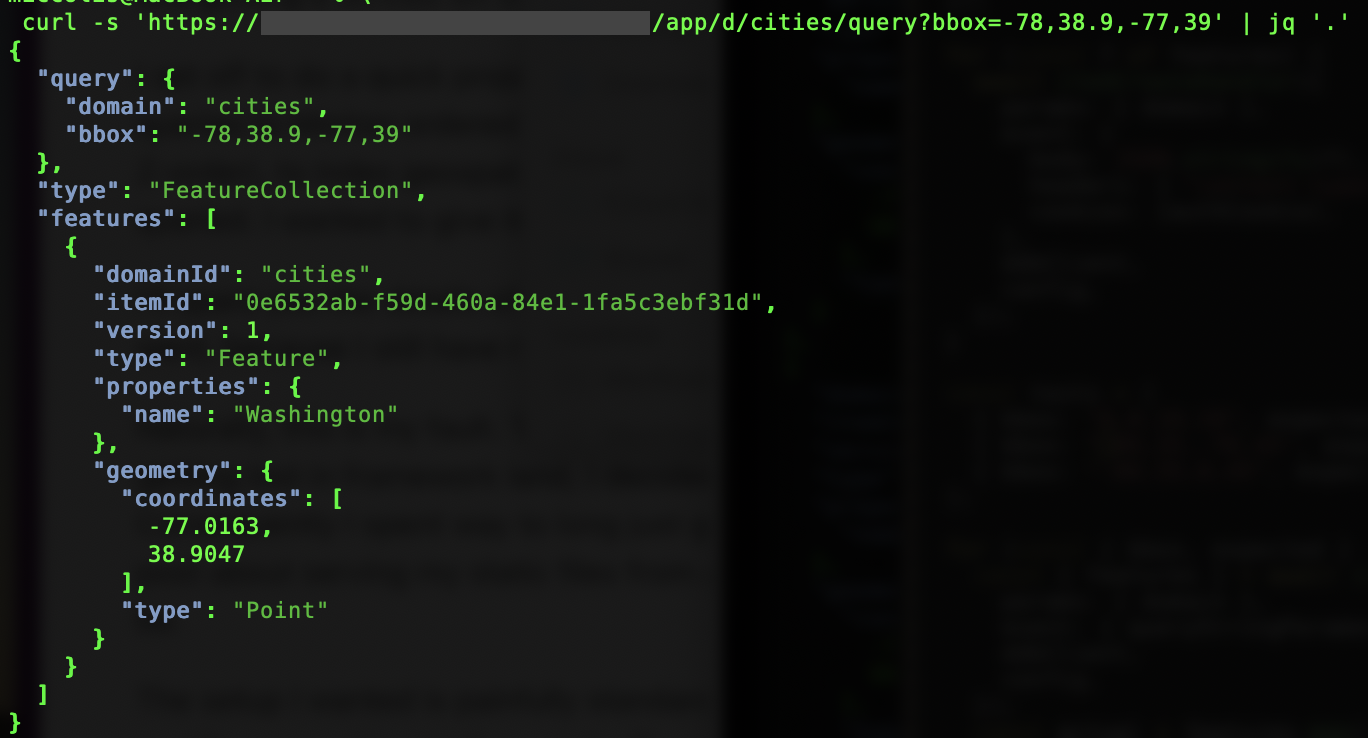
I’ll spare you the details of what I had planned for the optimization and I can’t tell you how it went, because I still have not gotten to it.
Naturally, this is my fault. To keep myself honest about re-learning how things work and avoid getting lost in framework land, I decided to work with primitives as much as possible. Consequently I spent way to long getting the application hoisted up on AWS. This is a blog post about serving my static files from AWS S3, because it’s not nearly was easy at it should be.
The setup I wanted is painfully standard. A web app with some static files served from S3 and an API powered by AWS Lambda. Then rules for routing requests would live in AWS’s CDN, Cloudfront, and would look something like;
GET http://my-website.com/index.html -> AWS S3
POST http://my-website.com/app/login -> AWS Lambda
To do this I’d imagine something like one resource for the Cloudfront distibution and one for each backend. The minimum to get it working is only slightly more complicated. Instead of a single resource for each origin you need two. It’s kind of a lot, but maybe not too bad.
Sadly it’s insecure. Really you should only have access to the files on S3 when going through the CDN. Getting access properly managed is 3 more resources. That full list looks something like this;
AWS::CloudFront::Distribution // the request routing rules AWS::CloudFront::OriginRequestPolicy // how to request things from S3 AWS::CloudFront::CachePolicy // when to cache data from s3 AWS::CloudFront::OriginRequestPolicy // (2nd one) how to do lambda requests AWS::CloudFront::CachePolicy // (2nd one) how to cache lambda responses AWS::CloudFront::OriginAccessControl // setup s3 request signing AWS::CloudFront::ResponseHeadersPolicy // Adds security headers AWS::S3::BucketPolicy // Grants Cloudfront access to S3
More than just the volume of config, getting this setup right is confusing and I’ve seen it done wrong on multiple occasions. Folks get so frustrated that they start opening up permissions to try to get it working. Then once it’s working they fail to retrace their steps and get things properly locked down.
It doesn’t help that Cloudfront presently has two ways to securely enable S3 access; “Origin Access Control” and “Origin Access Identify”. To make it more fun the documentation frequently uses the almost identical acronyms; “OAC” and “OAI”.
Reading (and re-reading) the docs I think I understand why they’d like you to use OAC and not OAI. It appears that the idea of having “identities” in Cloudfront that are the IAM “principal” did not pan out. Likely it started looking to much like a misplaced reflection of IAM and they pulled the plug on it. So the OAC has a ‘principal’ of Cloudfront itself & you use the IAM condition syntax to limit access to only the distro you want.
It’s a bummer how complicated this is.
The current recommendation for static site hosting is to use AWS’s Amplify framework. It’s built on top of CDK, which is itself an abstraction on top of Cloudformation, and it provides a huge number of features. I’m not kidding. They’ve packaged up all the things they know folks want, assembled them and made everything much easier. On paper anyhow. The draw back is that you have 3 levels of abstraction from the actual AWS resources you’ll be provisioning.
I’ve never used Amplify because I fear it has limitations that you don’t expect. Things that, when you run into them, make what was previously 30 minute config task, to a multi-day slog. Issues like this problem where Amplify resources do not support referencing auth configurations have me convinced they exist and are not fun.
Still, Amplify is much closer to the improved “enable static website hosting” feature that I wish S3 had. It’s a shame that you need to commit so fully to Amplify and it’s limitations to make things simple. Instead of continuing to layer on abstractions, it would be great if Cloudformation would tackle these problems. All the flexibility it supports completely overwhelms folks trying to do normal things. There was a book a about Perl that had the subtitle “Making Easy Things Easy and Hard Things Possible” and I wish Cloudformation would take that approach a bit more.